今年玉山比賽真的很充實,幾天以來也已經看到許多強者貼出比賽心得了,例如
玉山 NLP 應用挑戰賽、玉山人工智慧公開挑戰賽 2020 夏季賽 — Brainchild。
NLP 底子沒有那麼深厚的我在佩服之餘,也思考能夠如何回饋給社群。我想我的特殊之處在於身為一個一邊比賽、一邊從頭學習 NLP 的新手,我希望也能夠給和我一樣缺乏基礎的人一些思路上的參考。
這篇文章主要目的是分享我的作法,以及我是如何在有限時間內從 0 經驗推進到打造出一個初步可行的解方。我本身是碩班開始念統計,只初步以自學得到有限的深度學習知識(大概知道backpropagation、activation function、Optimizers 等大致概念),之前也完全沒有接觸過自然語言處理。但我知道這個領域正蓬勃發展,比賽前看到很多文章討論 OpenAI 釋出超大模型GPT-3(例如這篇),就躍躍欲試,很想找機會好好了解這個領域。
比賽那麼多,玉山的有什麼特別?
現在外面的機器學習相關活動和比賽像雨後春筍一樣冒出,玉山每年也都會舉辦資料科學或機器學習相關比賽,今年(2020)的比賽和往常不同的特點在:
- 題目是 NLP 應用相關
- 比賽方式並非直接上傳 submission,而是呼叫 API 進行預測,更貼近實際應用場景(因為 API 的形式更為靈活,可以即時可以批量,也可以很輕鬆地更換模型版本或者是給不同的人使用)
對於比賽的期望
基於以上原因,我很快報名比賽,這次比賽過程,我主要希望能夠學習:
- NLP 的概念與實務應用
- 佈署模型到 API Server
比賽主題
1 | 目標 : 判斷該新聞內文是否含有洗錢防制 (AML) 相關焦點人物,並擷取出焦點人物名單(名單有可能為複數或為空) |
「模型訓練」進行方式如下:
參賽隊伍於 T-Brain 平台 Dataset Download 區下載訓練資料集,主辦單位提供新聞連結與該新聞對應的焦點人物名單,參賽隊伍需自行實作爬蟲程式獲取新聞內文。…
參賽隊伍須提供 RESTful API Server 並將模型部署於此 API Server,並以 API 服務形式供「線上對決 – 模型準度爭霸戰」使用…
「線上對決 – 模型準度爭霸戰」進行方式如下:
爭霸戰為期九天,包含一天測試賽(2020/07/22),與八天正式賽…
主辦單位將會使用 HTTP Request 方式驗證參賽者模型成效,每日多輪提問,每輪一題,…
將以模型擷取之名單準確度作為積分(詳見下方評分方式),並於每日 24:00 前於活動 Slack(channel # 公告區)公布當日累積積分排名,每日加總後積分為最終排名依據。

簡單來說:
- 全對會獲得一分
- 如果 truth 為空值而模型正確預測即可得一分
舉例而言,
- 如果 truth 為 [“邱秋蚯”,“邱譬丘”],全部正確預測可得一分
- 模型預測 [“邱譬丘”,“皮卡丘”] 可得 $2/(2+2)=0.5$;如果模型預測 [“邱譬丘”] 可得 $2/(1+2)=0.66$
- 但如果預測 [“皮卡丘”] 就是0分計算
Before starting
我花了一個週末 google 跟觀看李弘毅教授/Andrew Ng 教授介紹 NLP 相關概念的影片,從 word2vec,RNN 到最新的 Attention model…,大概了解自然語言處理發展的概念、脈絡,目前發展到哪。但還是不知道怎麼下手,所以我另外上 kaggle 搜尋筆記本,有很多筆記本有做相關的介紹,從最基礎到進階的介紹都有,是很好的學習資源。
Strategy
最簡單的策略:
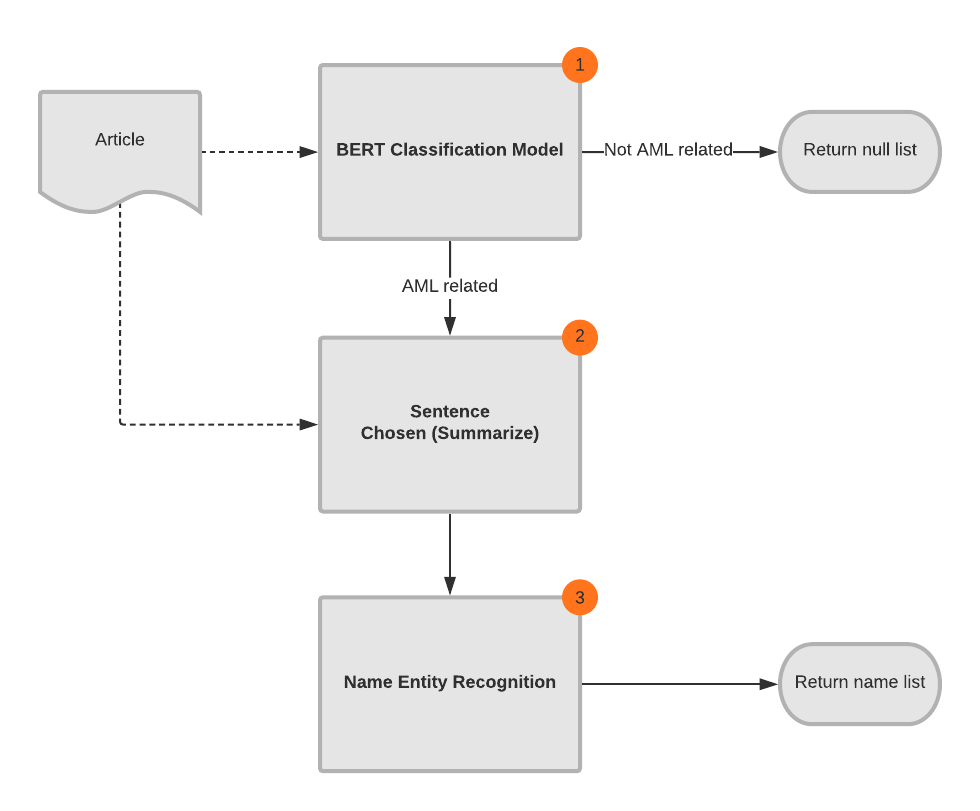
1 | 判斷是否為AML相關的新聞 (Classification) → 擷取關鍵句子 (Summarize)→ 擷取人名 (Name entity recognition) |
這個策略的重點在於擷取關鍵句子,如果文章中出現太多誤導性的句子,就會多出很多無關的人,例如記者、檢察官、法官,或是誰誰誰的兒女及兄弟姊妹等。像是:「創辦人陳XX之子、總經理陳XX被高等法院加重改判刑2年半」,當中第一個出現的陳XX 就是誤導的名字。
另一個我想到比較好的作法是:
1 | 判斷是否為AML相關的新聞 (Classification) → 擷取人名 (Name entity recognition)→ 指代消解(Coreference resolution) →句子分類,也就是那個人有罪無罪 (Classification)→累加 |
但這時候會出現一些我無法判斷規則的狀況,這裡舉一些例子,
- 「…另被檢方指控涉逃漏稅與偽證的農地買主林XX,也因罪嫌不足獲判無罪」,這篇林XX不在名單內,但
- 「.…並將李XX與洪姓父子等人提起公訴。一審依貪污罪…三審李無罪確定…」,這篇新聞李XX卻在名單內。
有鑑於時間有限、目前的能力亦還在起步,所以我選擇最簡單的策略,也就是上面第一種。
預測流程
Training
模型的訓練都借助 Colab 的 GPU,詳細的 code 可參考我的 Github。
Data
玉山提供五千多筆的 URL 與相應的人名,需要寫一個爬蟲把新聞內文抓下來,這裡麻煩之處在於總共有 39 個 domain,要再一個個仔細確認他們排版的格式。另外,要再根據有無列出焦點人物添加 IND 的標籤,如果該 URL 新聞內文已下架就直接從資料中刪除,如下:

1. 判斷是否為 AML 相關的新聞
Classification model 對我而言是相對簡單的,遇到的當時想,如果這關能做出來,後面應該也是花了時間就能夠解決的。上網搜尋一下,我很快就發現 transformers,簡單易用,可以直接借助 BERT 的威力,再加一層 dense layer 進行 fine-tune;此外還有很多中文的 pre-trained model 可以嘗試。
效果非常好,val_acc 在 3 個 Epoch 後達到 0.96, f1-score 也有 0.86,只能說 BERT 真的強大。
1 | import transformers |
2. 擷取人名
擷取人名的部份稍微麻煩些,要幫每個 token 做標記,起初我直接上 Github 搜尋關鍵字找相關的 repo 跟資料集,想用同樣的模式以 transformers 在 BERT 上面再架一層 GRU。但中間出現各種 bug 解不了,此時剛好發現 **kashgari--**它包含了一些 NLP 模型的框架,其中有實體辨識(NER)相關模型的 API,還有整理好的資料 ChineseDailyNerCorpus--發現訓練的效果還不錯(人名辨識的部份 f1-score 有 0.96,但缺點就是沒有就 BERT 的部份進行 fine-tune),我就決定先拿來用。後來想想如果自己有下去資料標注,NER 模型可能會有一些分類的效果。
1 | from kashgari.tasks.labeling import BiGRU_Model |
3. 擷取關鍵句子
關於要怎麼篩掉不需要的人名,我一開始直接使用 snownlp 進行 summarize,篩選出大約 20 句摘要句子,原本想說不重要、不會重復出現的人名就不會被選出來。但到比賽後期發現這樣行不通,還是會被選出來(笑),因為如果句子選的少很可能遺落焦點人物,選的多閒雜人等就會進來。一篇文章通常有多個非關鍵人物或者受害者的名字,例如上面提到過會混雜記者、該案件法官、檢察官等,需要另一個模型判斷哪些句子該納入。於是我就用暴力解法直接幫每個句子標註標籤,做出一個分類模型。
其中,同時有人名與犯罪事實的就標註 1 ,例如:
「高XX與同夥8月1日被台中地檢署查獲涉嫌販賣海洛因及安毒」
然而,如果無關則標註為 0 ,例如:
「記者陳XX/綜合報導台南市一名李姓女消防員被控有火警時」
「前中華電信董事長、交大榮譽教授呂XX,今年7月間接到冒充特偵組檢察官的詐騙集團來電」
含有不相關人名的我也一律標註為 0,例如:
「陳XX長女即副總陳XX1年」
這樣可以盡量避免納入不相關人名,當然這樣只能刪掉一些明顯不要的句子。加入句子分類模型後每日分數從 365,366 進步至 371,但已經是比賽最後一天了,開竅太晚的我眼看大勢已去,只能唯見諸位強者長江天際流(笑)。
API server
我直接使用玉山提供的API教學內容,使用 Flask (web framework) 在 GCP 上佈署,詳細過程就不在此贅述。
After Competition
一開始抱著學習的心態,沒有想過能夠進入前面的名次,所以第一天發現自己有 30 名時超開心,重新把第一步的分類模型重新訓練,加長 tokenize 的長度,準確率果然進步至 0.99,分數也從 350 進步至 365。
謝謝隊友們被我任性拉來比賽,雖然後來隊友因為工作忙碌所以沒辦法再參與,但一開始的起頭讓我不孤單。在這場比賽我基本上就是靠 BERT 而已,自己貢獻的範圍其實很有限,但也見識到了目前自然語言處理的強大,這應該是往後學習 NLP 相關知識的一個起點。
![]()
取得第13名的成績(13/409)